Recent advancements in Large Language Models (LLMs) such as GPT4 have dis- played exceptional multi-modal capabilities in following open-ended instructions given images. However, the performance of these models heavily relies on design choices such as network structures, training data, and training strategies, and these choices have not been extensively discussed in the literature, making it difficult to quantify progress in this field. To address this issue, this paper presents a systematic and comprehensive study, quantitatively and qualitatively, on training such models. We implement over 20 variants with controlled settings. Concretely, for network structures, we compare different LLM backbones and model designs. For training data, we investigate the impact of data and sampling strategies. For instructions, we explore the influence of diversified prompts on the instruction-following ability of the trained models. For benchmarks, we contribute the first, to our best knowl- edge, comprehensive evaluation set including both image and video tasks through crowd-sourcing. Based on our findings, we present Lynx, which performs the most accurate multi-modal understanding while keeping the best multi-modal generation ability compared to existing open-sourced GPT4-style models.
Our model takes simultaneously vision and language as inputs to generate text responses following the input instructions. Concretely, vision inputs are first processed by a vision encoder to get a sequence of vision tokens. After that, vision tokens are fused with instruction tokens for multi-modal tasks. In our model, we directly concatenate the projected vision tokens and instruction tokens as the input of LLMs, which can then be processed by the decoder-only LLMs naturally. We call this structure "prefix-finetuning" (PT)
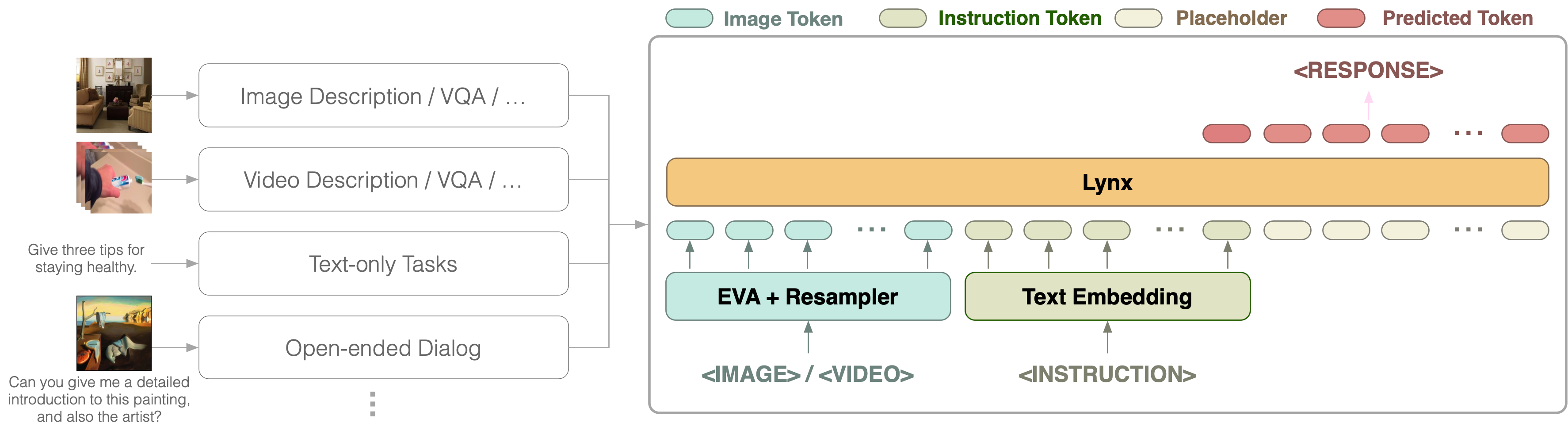
The architecture of Lynx.
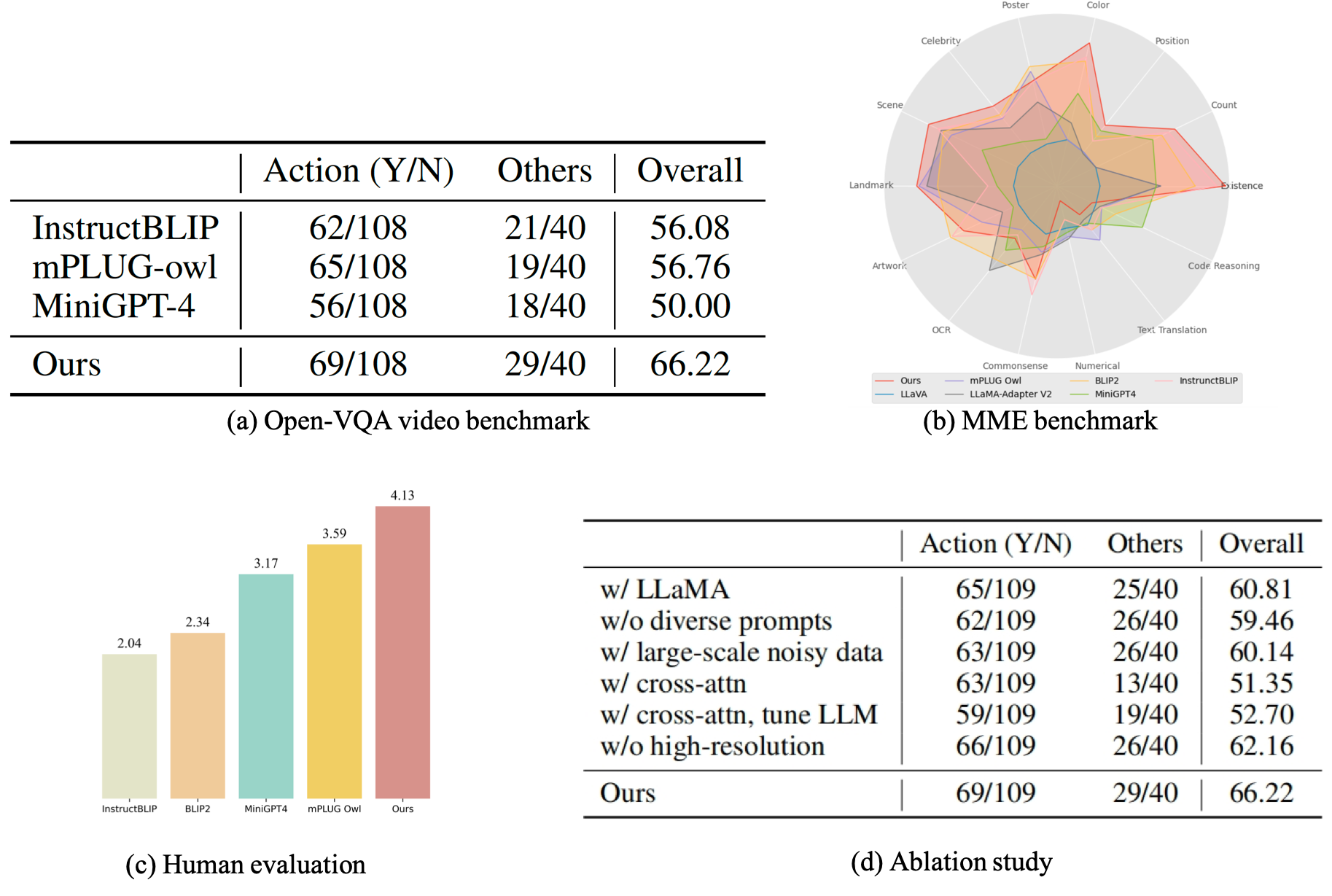
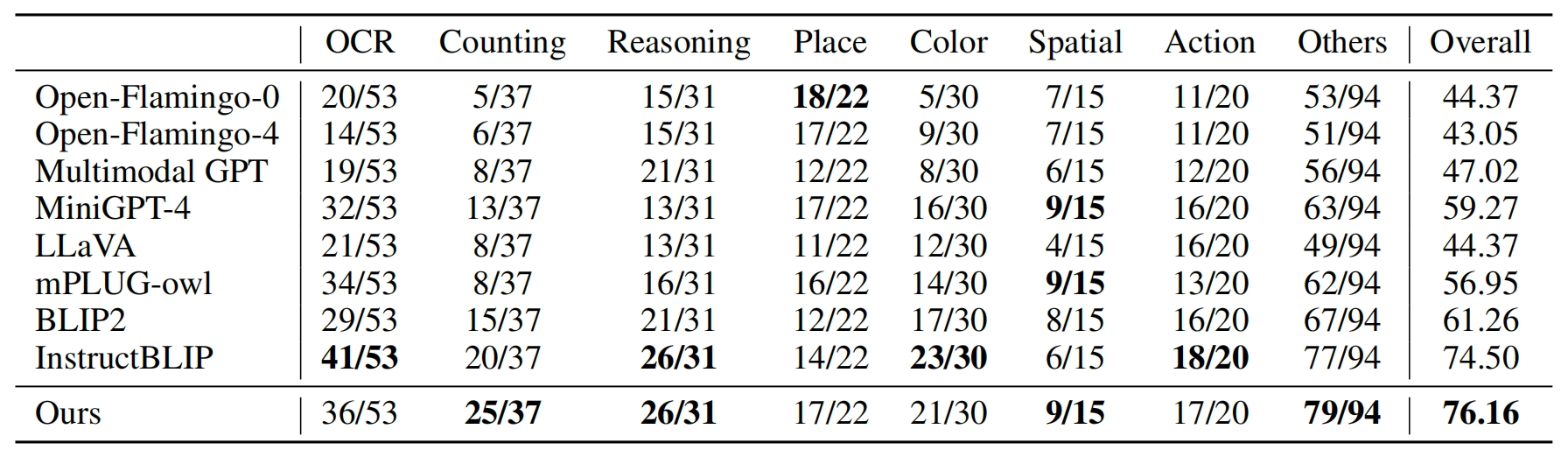
We first compare existing open-sourced multi-modal LLMs and quantitative evaluation results on the Open-VQA image benchmark, and then (a) benchmark them on videos; (b) benchmark them on MME dataset; (c) show human evaluation results, and (d) conduct an in-depth ablation study to investigate the impact of different components.



@article{zeng2023matters,
title={What Matters in Training a GPT4-Style Language Model with Multimodal Inputs?},
author={Zeng, Yan and Zhang, Hanbo and Zheng, Jiani and Xia, Jiangnan and Wei, Guoqiang and Wei, Yang and Zhang, Yuchen and Kong, Tao},
journal={arXiv preprint arXiv:2307.02469},
year={2023}
}